Multiple linear regression (MLR)
Sep 30, 2024
Outcome: Limit
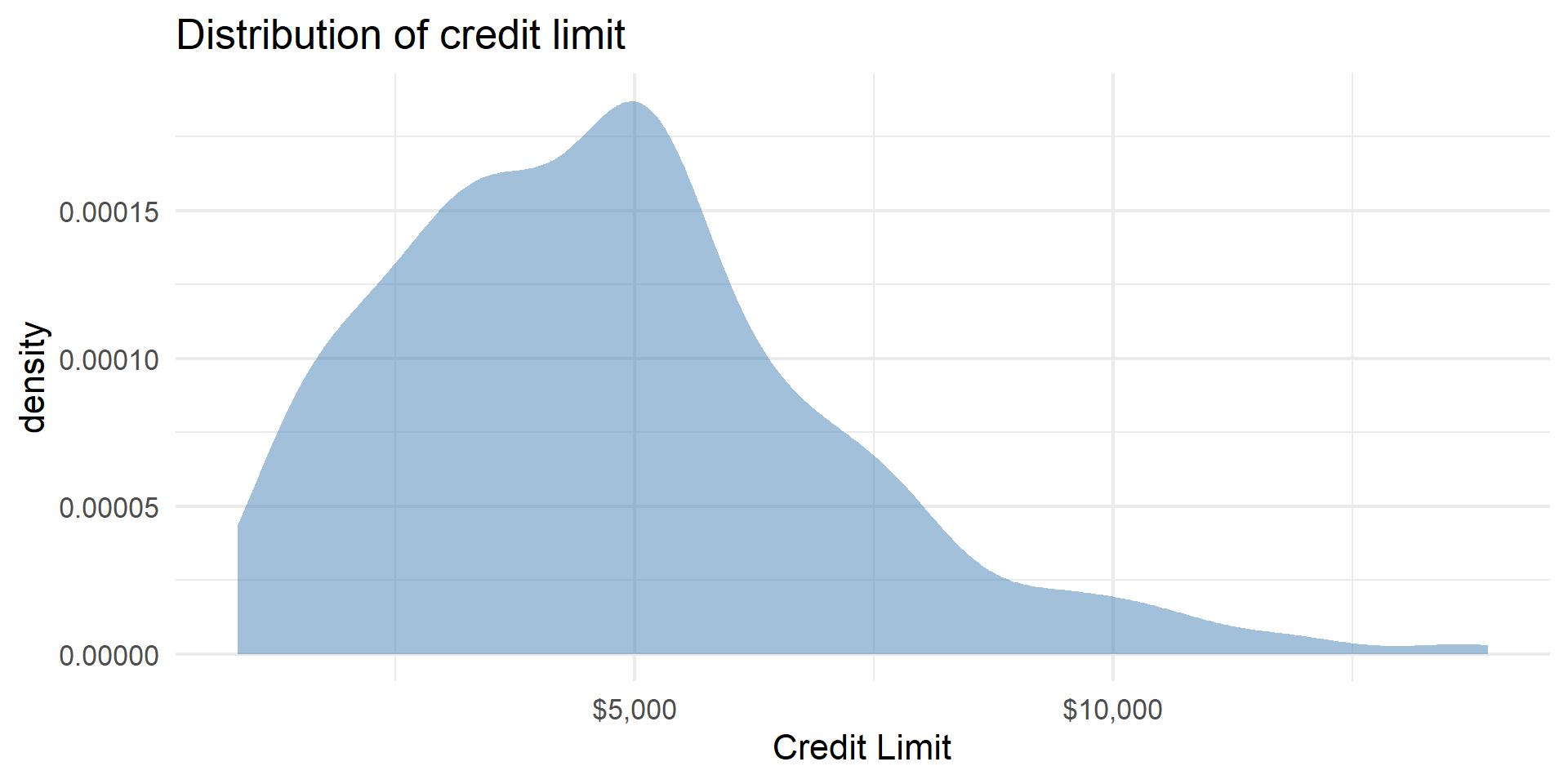
| min | Q1 | median | Q3 | max | mean | sd | n | missing | |
|---|---|---|---|---|---|---|---|---|---|
| 855 | 3088 | 4622.5 | 5872.75 | 13913 | 4735.6 | 2308.199 | 400 | 0 |
Predictors
Code
p1 <- Credit |>
gf_density(~Limit, fill = "steelblue") |>
gf_labs(title = "Distribution of credit limit",
x = "Credit Limit")|>
gf_refine(scale_x_continuous(labels = dollar_format()))
p2 <- Credit |>
gf_histogram(~Rating, binwidth = 50) |>
gf_labs(title = "",
x = "Credit Rating")
p3 <- Credit |>
gf_histogram(~Income, binwidth = 10) |>
gf_labs(title = "",
x = "Annual income (in $1,000s)") |>
gf_refine(scale_x_continuous(labels = dollar_format()))
p1 / (p2 + p3)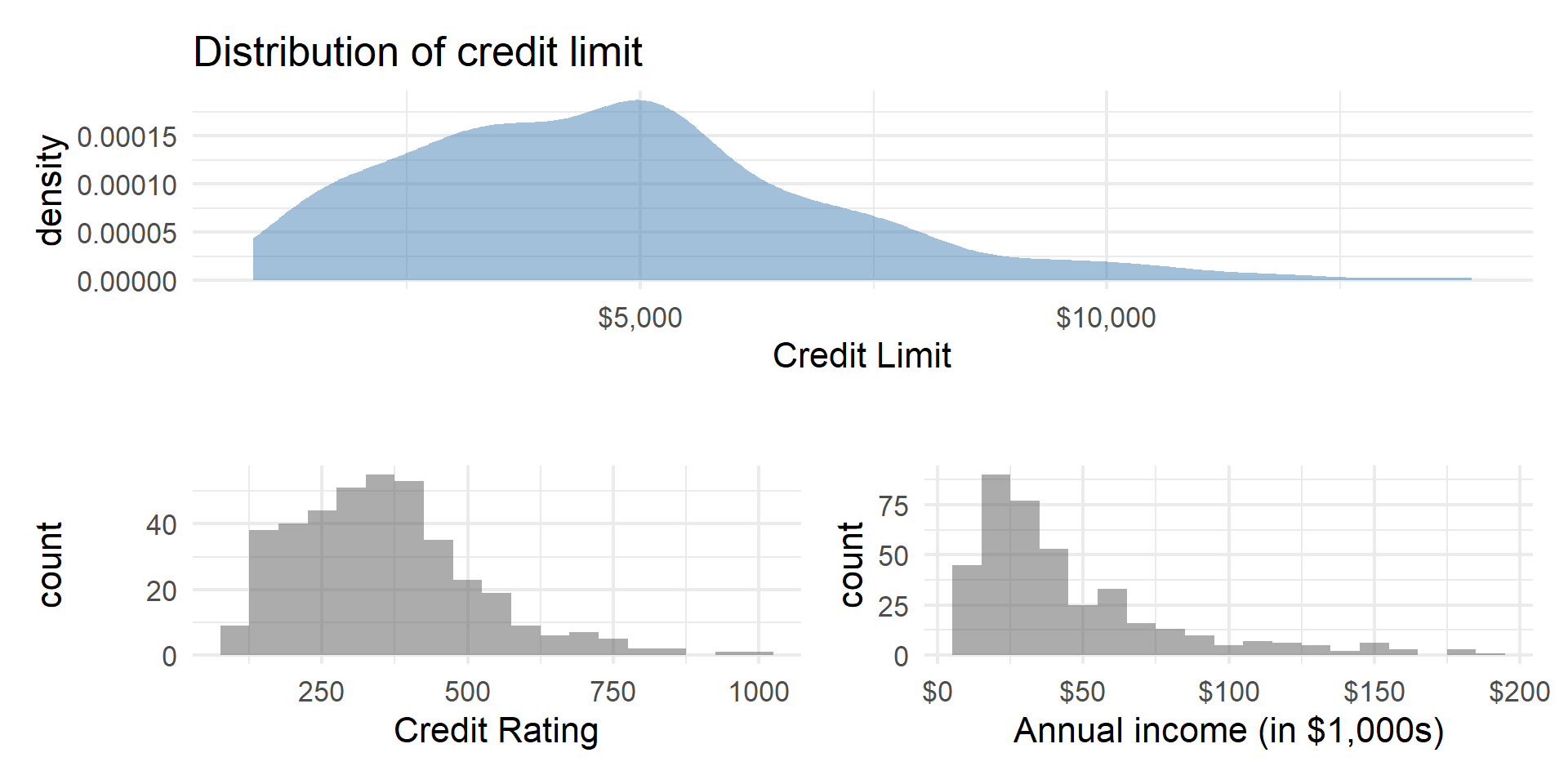
Outcome vs. predictors
Code
p4 <- Credit |>
gf_point(Limit ~ Rating, color = "steelblue") |>
gf_labs(
y = "Credit Limit",
x = "Credit Rating"
) |>
gf_refine(scale_y_continuous(labels = dollar_format()))
p5 <- Credit |>
gf_point(Limit ~ Income, color = "steelblue") |>
gf_labs(
y = "Credit Limit",
x = "Annual income (in $1,000s)"
) |>
gf_refine(scale_x_continuous(labels = dollar_format()),
scale_y_continuous(labels = percent_format(scale = 1)))
p4 / p5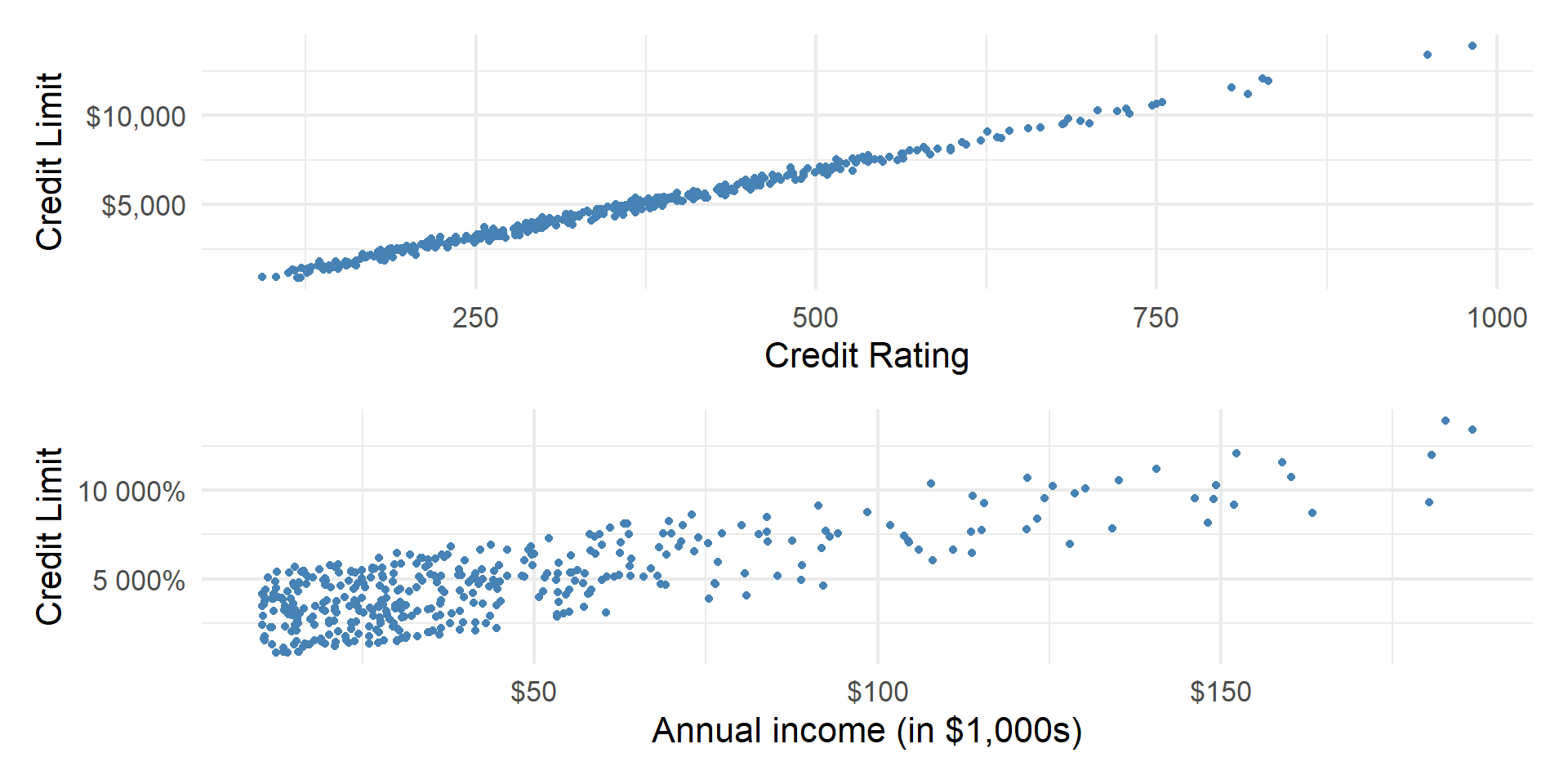
Cautions
- Do not extrapolate! Because there are multiple predictor variables, there is the potential to extrapolate in many directions
- The multiple regression model only shows association, not causality
- To show causality, you must have a carefully designed experiment or carefully account for confounding variables in an observational study
![]()