# load packages
library(tidyverse) # for data wrangling and visualization
library(ggformula) # for plotting using formulas
library(broom) # for formatting model output
library(scales) # for pretty axis labels
library(knitr) # for pretty tables
library(kableExtra) # also for pretty tables
library(patchwork) # arrange plots
# HEB Dataset
heb <- read_csv("data/HEBIncome.csv") |>
mutate(Avg_Income_K = Avg_Household_Income/1000)
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 20))SLR: Conditions
Sep 13, 2024
Mathematical representation, visualized
\[ Y|X \sim N(\beta_0 + \beta_1 X, \sigma_\epsilon^2) \]
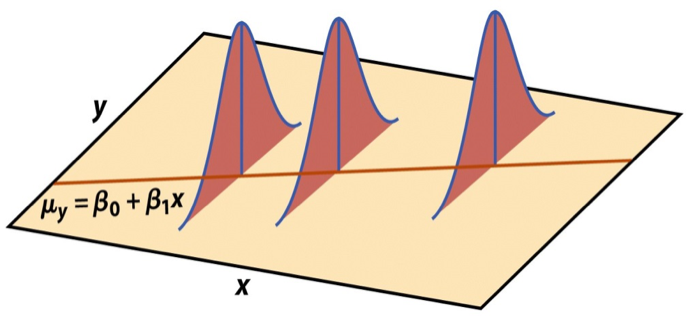
Image source: Introduction to the Practice of Statistics (5th ed)
Linearity
✅ The residuals vs. fitted values plot should show a random scatter of residuals (no distinguishable pattern or structure)
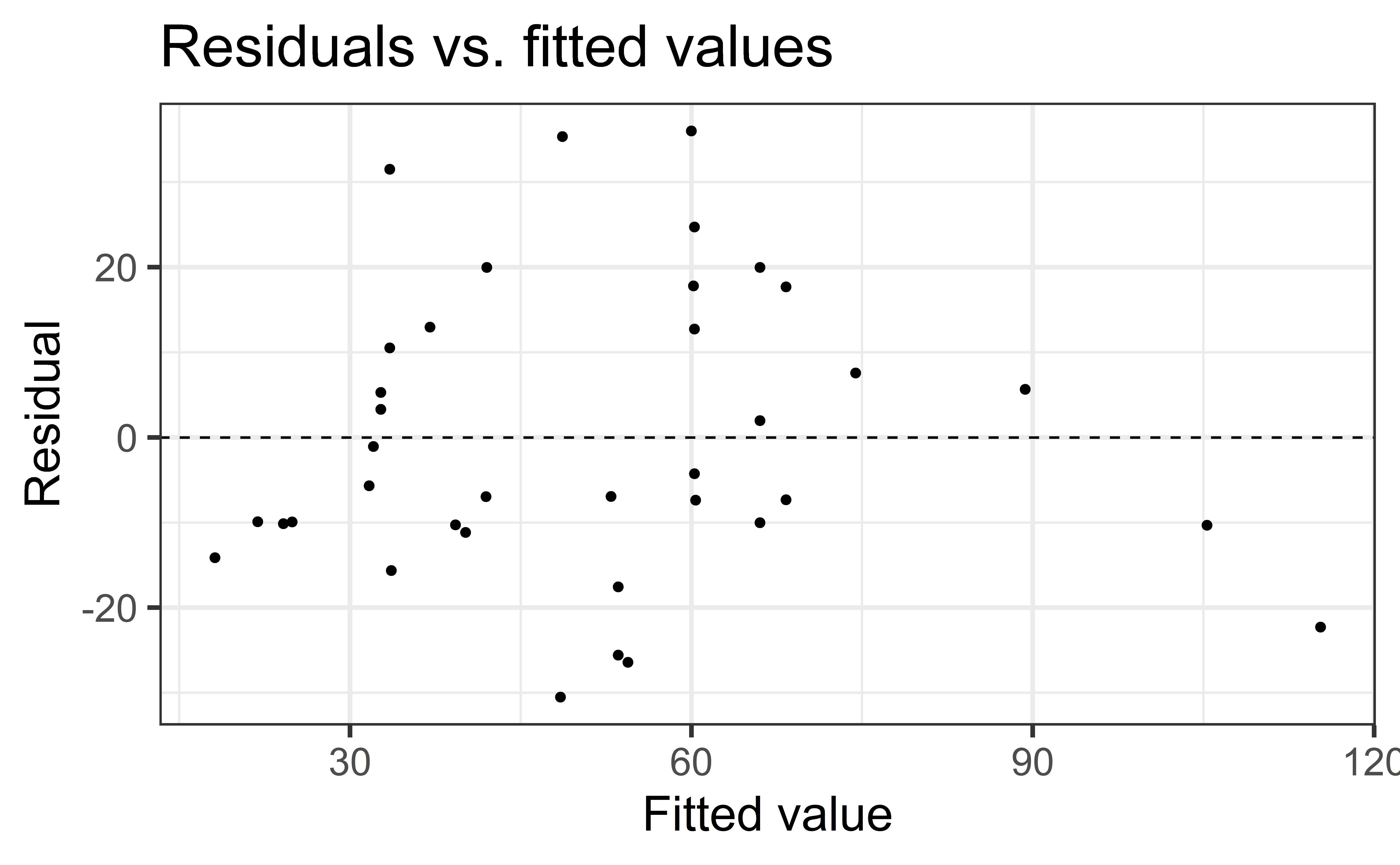
Non-linear relationships
Constant variance
✅ The vertical spread of the residuals is relatively constant across the plot
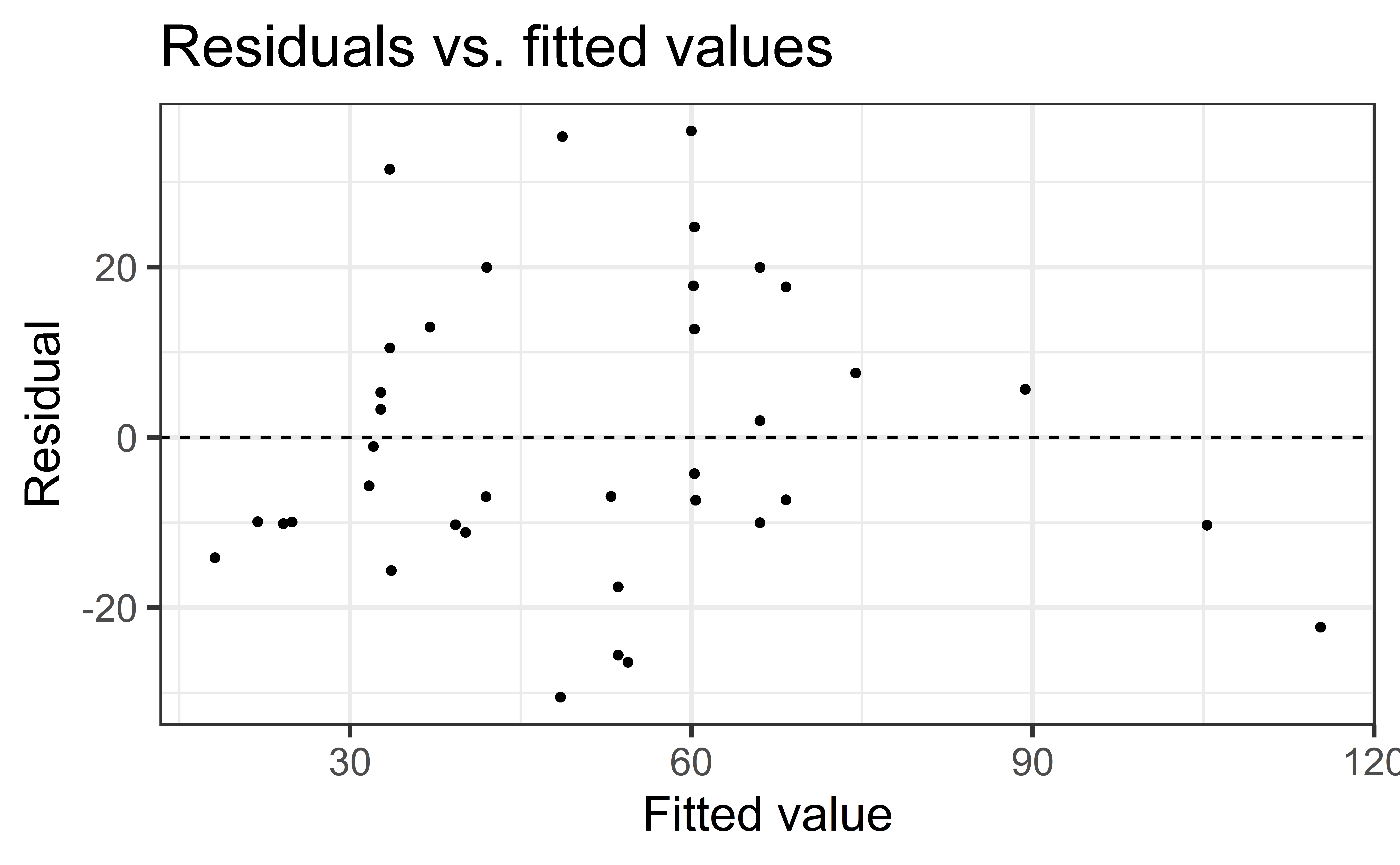
Non-constant variance
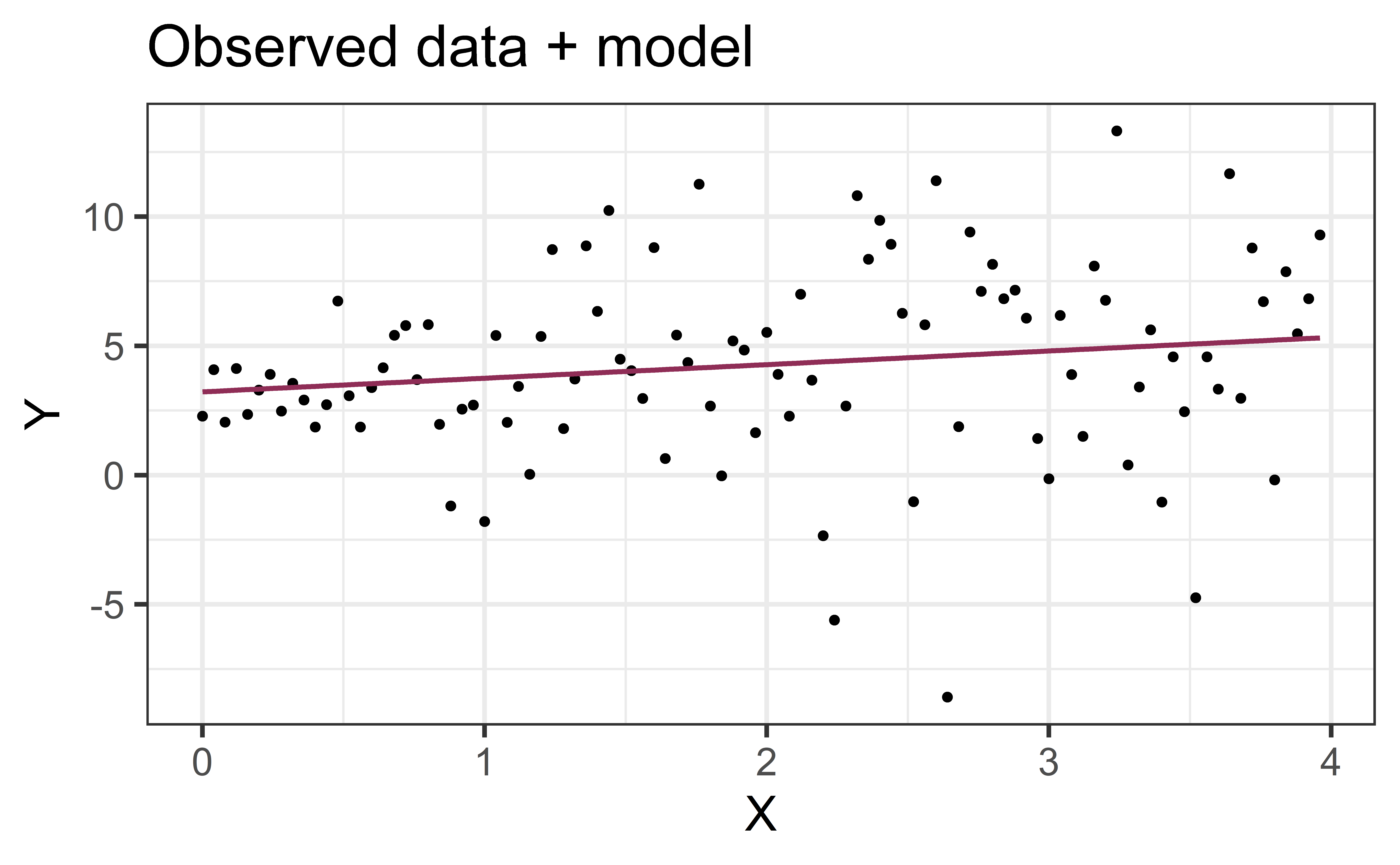
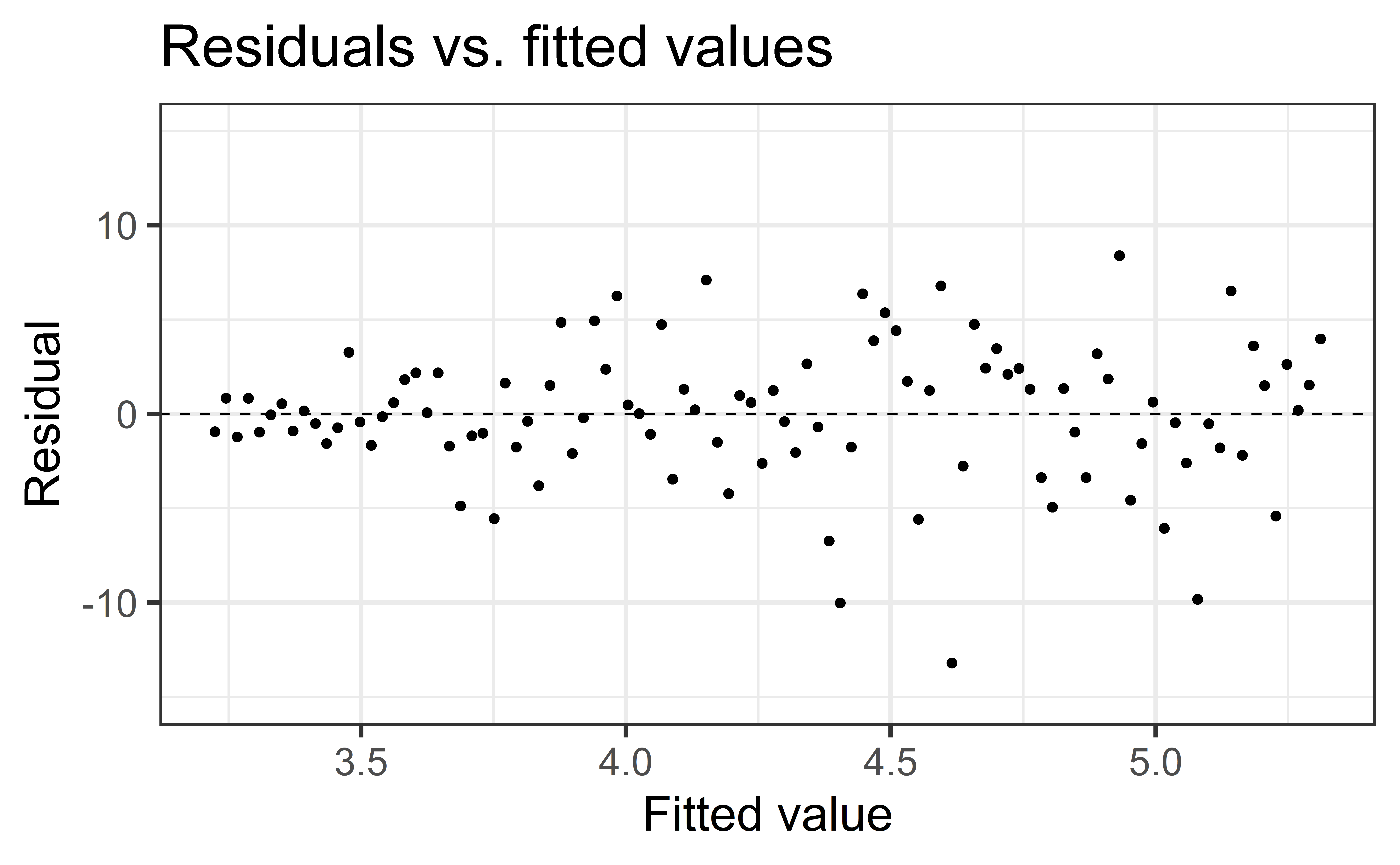
- Think: Is my error/variance proportional to the thing I’m predicting?
Normality
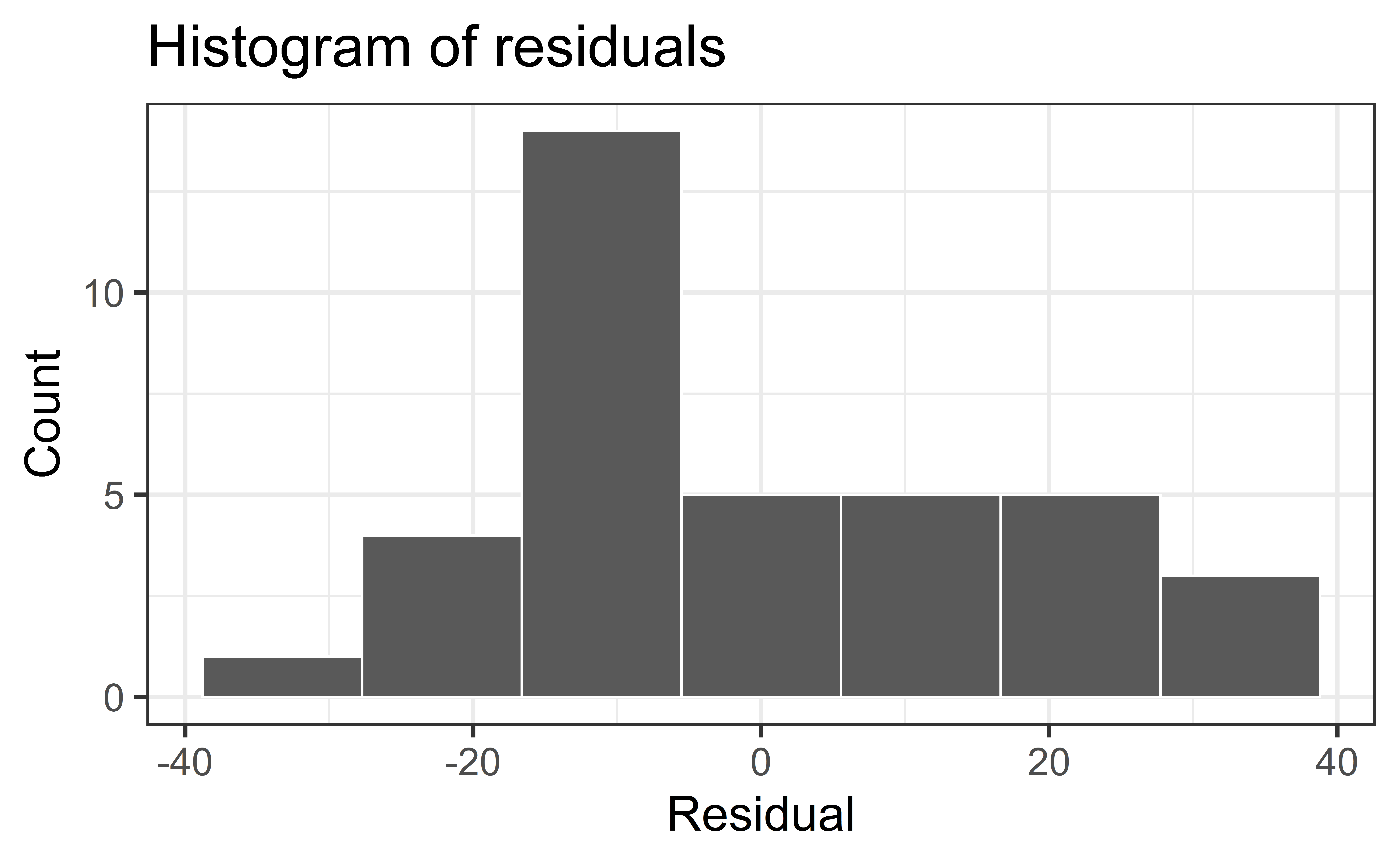
Check normality using a QQ-plot
Code
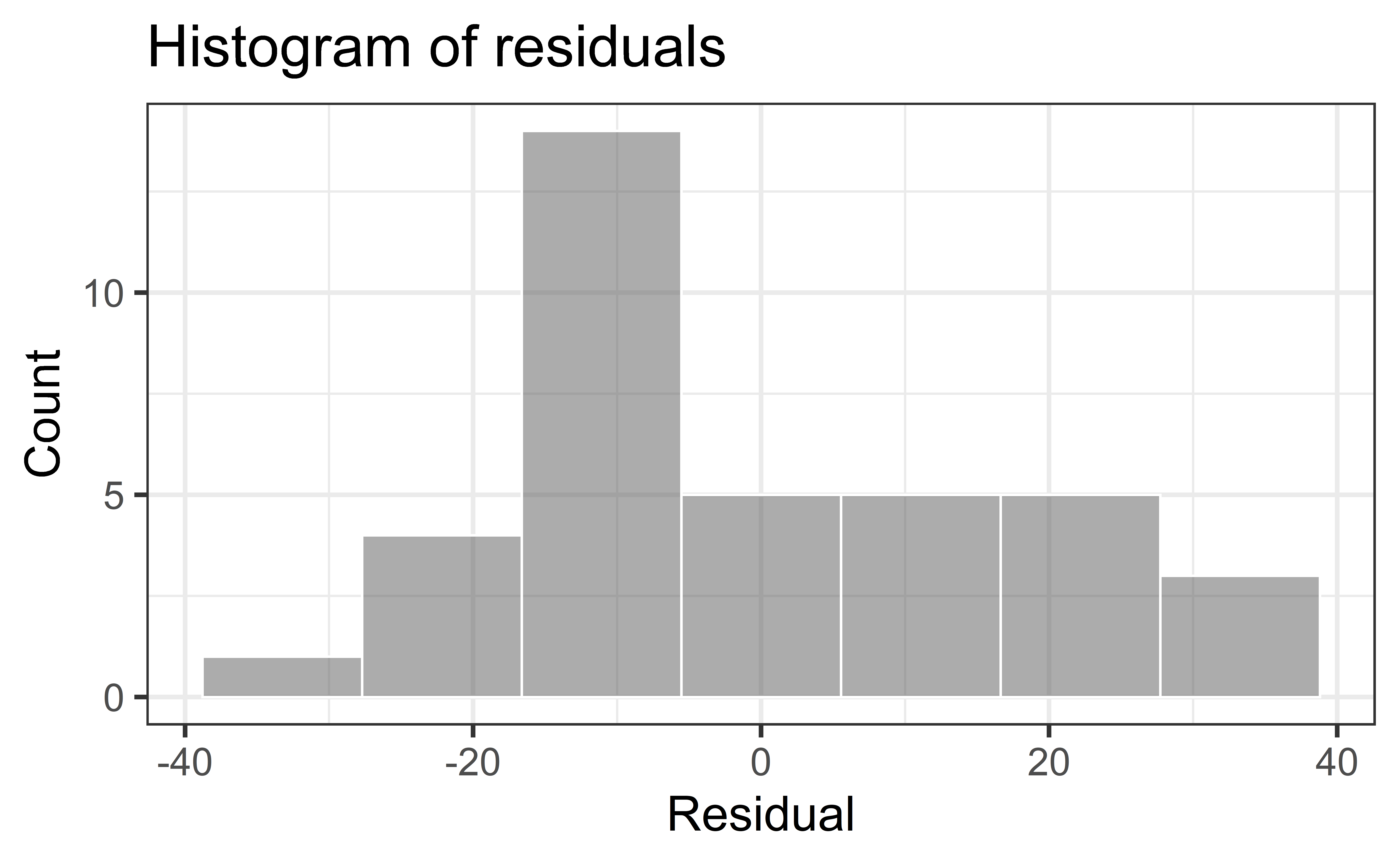
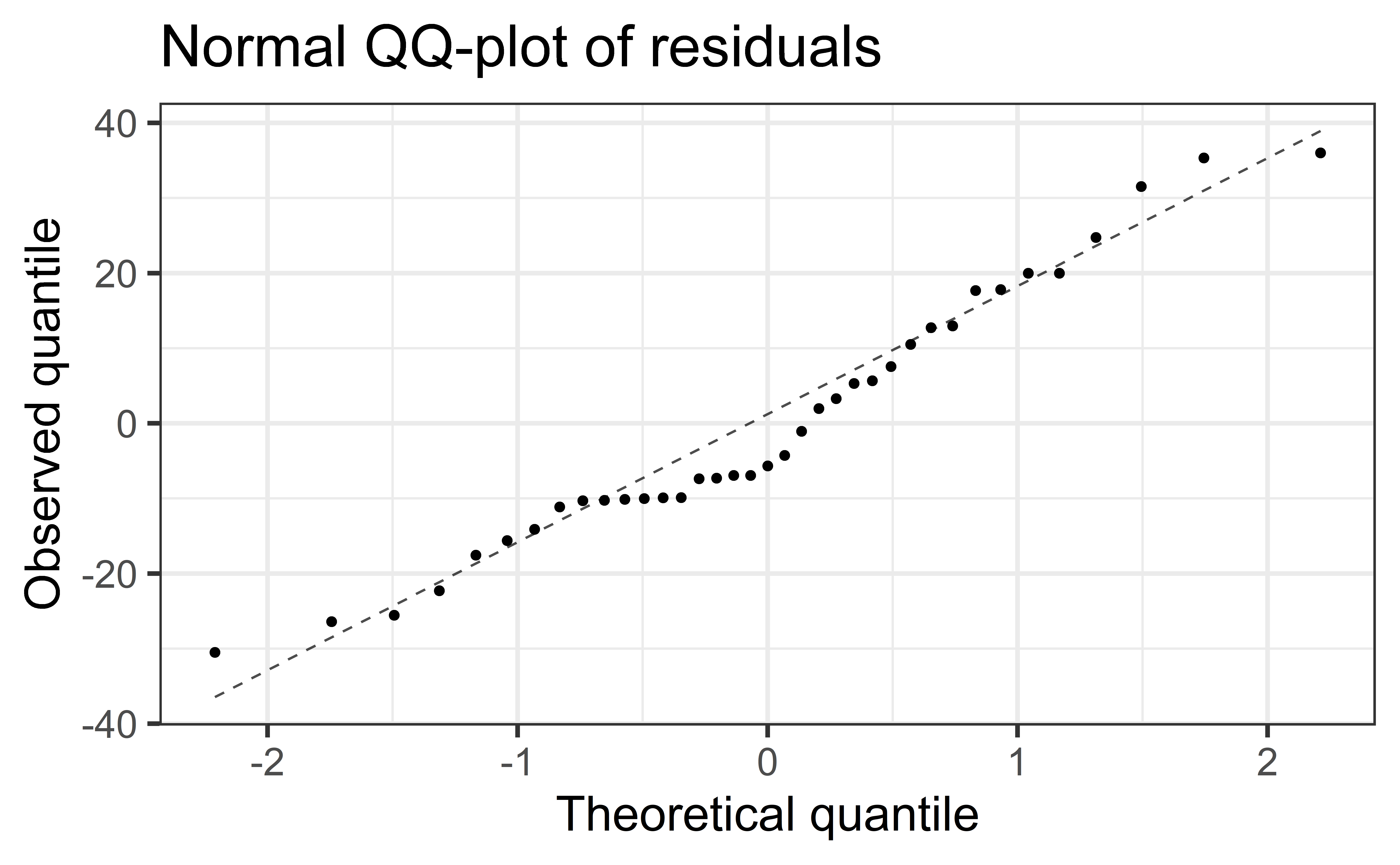
Assess whether residuals lie along the diagonal line of the Quantile-quantile plot (QQ-plot).
If so, the residuals are normally distributed.
Normality
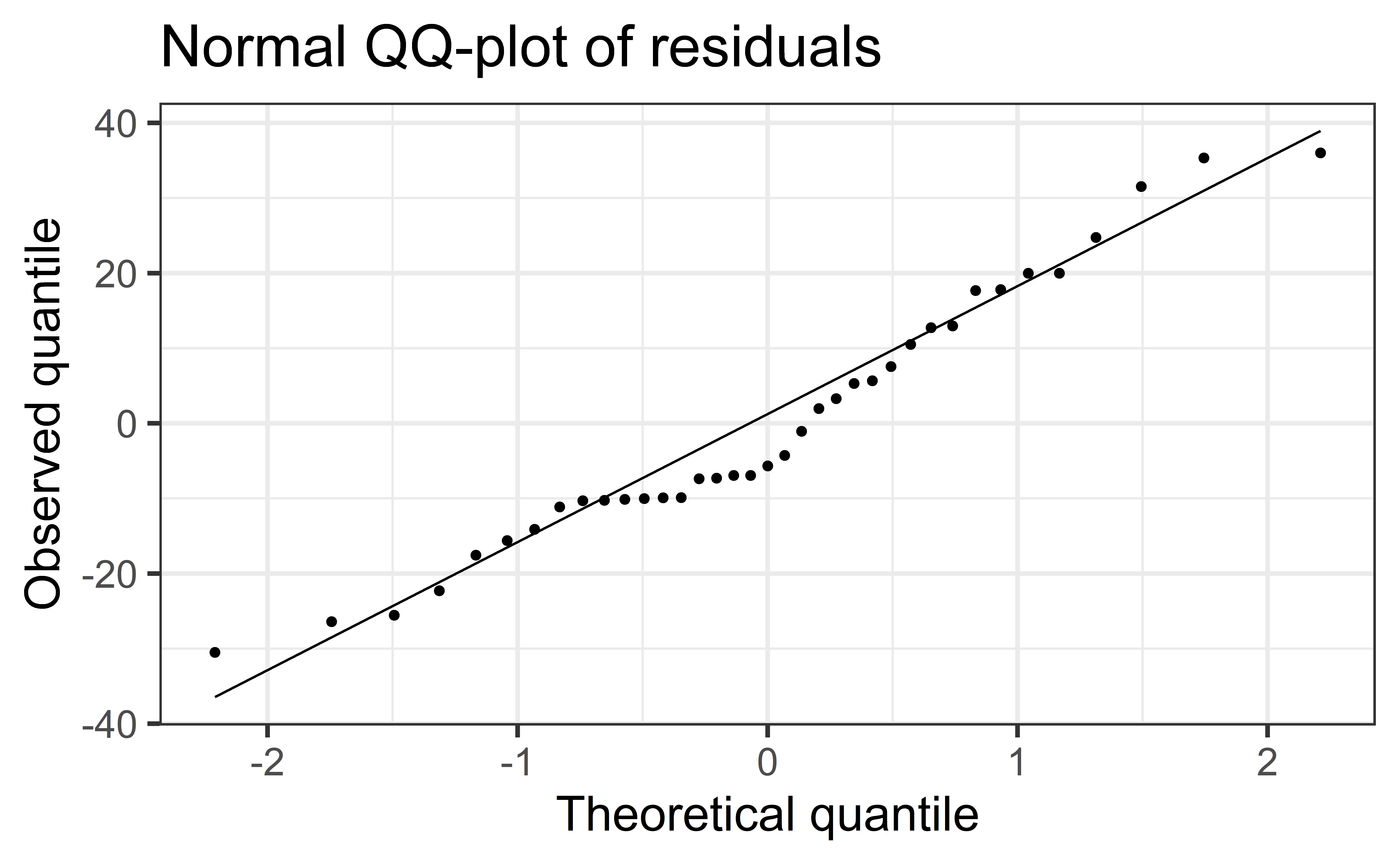
❌ The residuals do not appear to follow a normal distribution, because the points do not lie on the diagonal line, so normality is not satisfied.
✅ The sample size \(n = 37 > 30\), so the sample size is large enough to relax this condition and proceed with inference.
Recap
Used residual plots to check conditions for SLR:
- Linearity
- Constant variance
- Normality
- Independence
- Which of these conditions are required for fitting a SLR (and not doing any inference)?
- Which for simulation-based inference for the slope for an SLR?
- Which for inference with mathematical models?
03:00
![]()